You keep using the word sangha in a way that’s not in line with the EBTs. Also, splitting the actual sangha is one of the most grave offenses to accuse someone of, so please consider what you are doing when you say that.
FWIW, I don’t see any splitting going on. Just people having a heartfelt discussion about a very serious matter. Naturally there will be strong opinions. That’s ok. As Buddhists we need to be able to do that.
I think people may be taking this personally in an unhelpful way. I don’t see anyone shaming people who use LLMs/MT in their personal lives to solve personal problems. Perhaps people who are feeling that this is happening could start by using some “I” statements to share their reactions.
Even though Suttacentral.net can be 100% AI-Free, sc-voice.net and all its related websites cannot by 100% AI-Free. The primary reason is the use of AI for text-to-speech. Although Bhante @Sujato has permitted that use, Ayya @Sabbamitta and I have been having discussions about licensing and use of SC-Voice. Given the rapid pace of events in this thread, we’ve spent some time preparing a draft of our proposed license structure.
You will notice that there are three inclusions that bring up interesting questions:
Code of Conduct encourages people to investigate Buddhist values for themselves in the use of this content
Ethical AI itemizes and explains the restricted use of AI
Great Reference introduces users to the concept of preserving the integrity of the teachings. Q: Is all Bilara published content a candidate for consideration as a “great reference?”
This is an attempt to integrate the suttas into a statement of license and use for AI involvement in Buddhist teachings.
NOTE: After reading the Great Reference, I have decided to delete the ebt-deepl content from sc-voice simply because that content can never be verified as a great reference for anybody’s use, not even mine. See what happens when you read the suttas?
Thank you, Ayya @Sabbamitta for the reference to AN4.180.
To repeat what I’ve said to you in a message, I think we should make a blanket exception for accessibility purposes. The work you have done is incredibly valuable, and you’ve made the Dhamma available in ways that have never been possible before.
The only thing I would say, and this may well be the case already, is that the user should be made aware that this is a machine voice.
I was struggling with understanding the rationale for that exception. Questions came up such as:
Is illiteracy an accessibility issue?
Is summarization an accessibility issue?
etc.
What helped me a lot is reading AN4.180. That sutta helped take me from the world of “yes we have Klingon suttas” to the definition and exploration of “sacred”, which you used and which I now understand in the context of AN4.180. It is the Sangha’s sacred duty to preserve the integrity of the Buddha’s teaching and the Buddha explains this for even the lay people to understand how and why this is sacred. In particular, no matter how smart AI gets, it can never be a great reference since I really cannot see how AI can live by the suttas in body, speech and mind for all to see.
I don’t want to further contribute to the discussion, and I certainly don’t want to take sides, but this is a suggestion for those with an open mind.
It may be helpful to learn more about what AI is, and in particular LLMs. That way, you can make up your own mind about the suitability of AI in relation to Buddhism and in particular translating Buddhist texts.
It is possible for you to run an open source LLM on your own computer, and not rely on our tech overlords. That way, you can do your own fine-tuning, and perhaps train the model to be Buddhist specific. Your conversations are also private, since everything is running on your own computer.
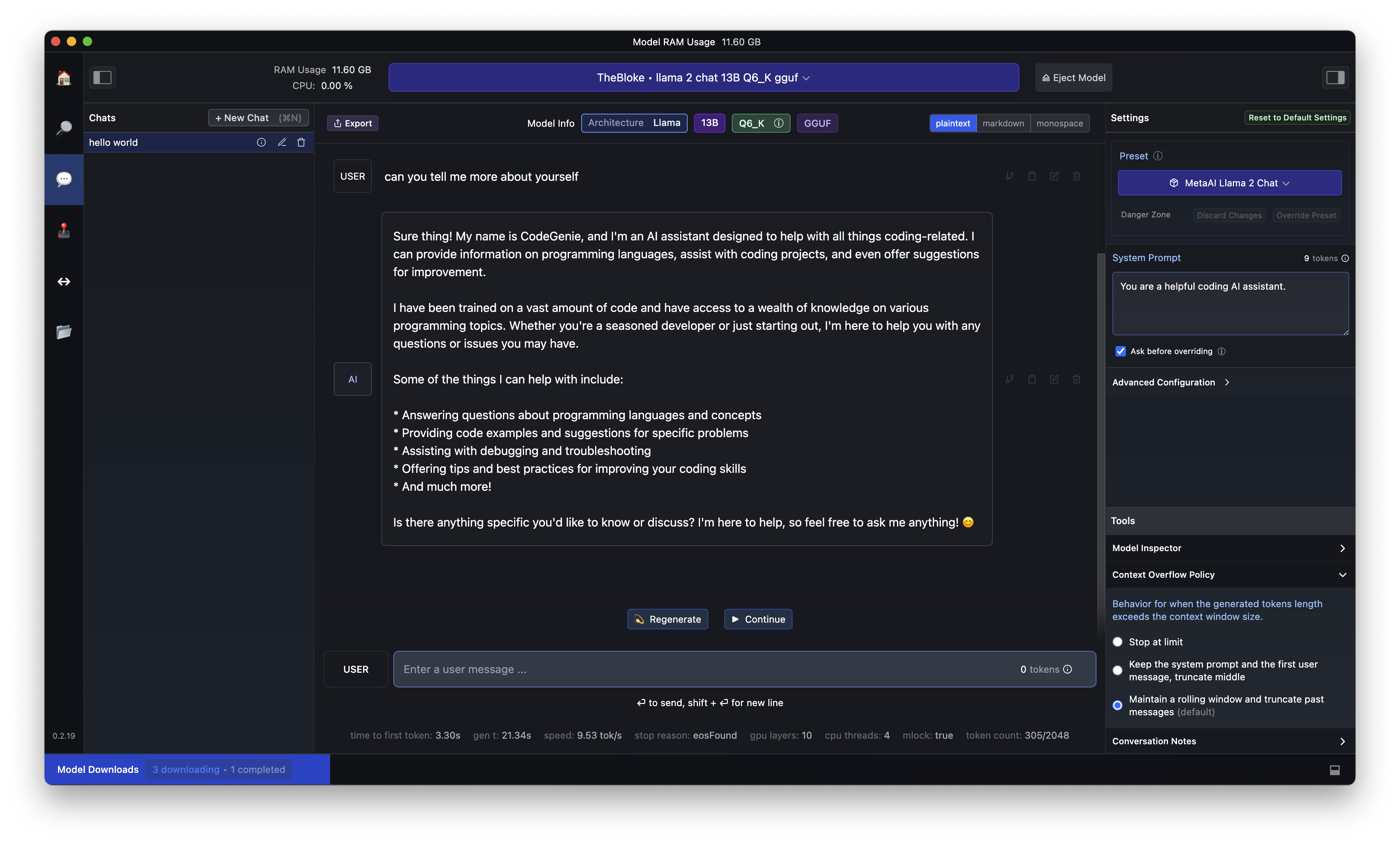
I suggest downloading the following app called LM Studio which allows you to use various open source LLMs (I recommend Llama from Meta, or Gemma from Google, or Claude from Claude.ai but feel free to try others such as Mistral)
Here is a screenshot of me running Llama on my computer using the default system prompt (“You are a helpful coding AI assistant”)
Yes. Indeed. I’ve been tracking that use and anticipate that I will need to do that for my own needs. That local LLM would do many things for the blind:
weight foodstuffs in the kitchen
make appointments
play suttas from SuttaCentral via SC-Voice (which already accepts spoken input in browser. E.g., I can say “root of suffering” and we’ll be able to play those suttas as a playlist. No need for AI–it’s already built into SC-Voice as plain old software. Oops I revealed the feature I’m supposed to be implementing for Ayya. )
Current voice assisted technology is in TI speak-and-spell age. Thank you for your recommendations.
I agree. There’s also not even a clear line between “AI” and “not AI”
Do users of Bilara need to turn off spell check / autocomplete when writing translations? Or are these “accessibility features”?
@Snowbird tells me that you (Bhante @sujato) had recently expressed an interest in incorporating the DPD’s compound splitter into the Pāḷi Lookup tool? This is also an unreliable AI, likely to create misunderstandings of the Pali and Dhamma (as indeed happened in our Pali class, for example). Does the Pāḷi Lookup Tool need to be stripped out of SuttaCentral? Certainly “not knowing Pali” isn’t an accessibility issue…
I believe that SuttaCentral is currently using CloudFlare as a reverse proxy? Because they use AI to filter out malicious requests and to decide what resources to cache. So SC needs to stop using CF and expose itself to the open internet?
Not much longer. Those fictional language translations were done by MT and are being removed.
I assume that when Bhante is using the word “accessible” he is referring to things disability related. Therefore the “inaccessibility” of commentarial texts is not a disability related issue since they aren’t translated for anyone into English.
I’m feeling a little unsure about the direction of this discussion because it seems like a lot of whataboutisms. I’m going to assume these questions are made in good faith, but I’m not really confident in that assumption.
It’s funny that you mention this because I was just now thinking of the voice synthesizer module on my TI994a back in the 80’s. Personally I don’t feel like text to speech has made very much progress since then and I’m wondering exactly how “AI” is being used the the TTS that Voice uses. It’s not bad, but it’s certainly not even close to amazing. It may be a discussion for a different thread, but I’m curious how “AI” is helping with that TTS since you keep bringing it up.
AI is quite good to give the user some idea of what the mysterious untranslated commentaries are writing to some idea. They are not perfect, and as said above, can lead to misinterpretations. However, if you listen to Sayadaw U Silananda’s talks on the vsm, almost every single talk has quite a few serious mistakes related to the interpretations of the tika translations made without AI long ago. AI is probably going to make similar literal mistakes. I think those mistakes have been fixed in later editions of the bps vsm. It would be interesting to see how AI matched up to some of the most complex pali there is.
So mistakes can be made and while many of the books have been translated in the native theravada languages, this is not the case for the translations in the english language.
Learning pāḷi is similar to learning a hand craft or a hobby. Perhaps Black and White photography and developing film. I’m sure the hard core photographers rejected color, and then others rejected digital. Now digital photography is far better than actual film but it was not always that way, especially when it first came out.
Digital Pali Dictionary Deconstructor does give a choice of words and does a good job, but is not perfect too. Another dictionary released by dpd and creator of tpr is called Pali English Ultimate (Myanmar Abhidhan) was originally a Myanmar Google Translation Project with many mistakes. Some of these mistakes were very humorous and obvious. However, it has been 75-80% edited by humans and is pretty good now. So editing is important. Often digital projects are “ongoing and rolling releases” as a new standard.
As stated above… a 5 full day translation project from a translator could be edited by a professional in 3-4 hours. The best of both worlds would be for getting the ground work translations done by AI and then editing them by a human. There was resistance to using AI in programming, but now, it is a necessity for saving time, and saving a lot of time. Hopefully the pāḷi community can see this. No doubt there needs silled editing to be done before publishing. On the other hand, AI can be a shortcut that bypasses the editing and publishing feature. Just as I often look up the meaning in gpt+ of untranslated commentaries right now.
Nevertheless, there is a joy in reading pāḷi in its native form, even if you take an excerpt study it well with other translations and then go direct to pali. There is still that joy in reading pāḷi directly. There are mistakes or stylistic choices if one uses a human translated version to understand pāḷi. I personally use AI to help me reading pāḷi directly, but also use the human translations as a basis. My least favorite translation is Ajahn Sujato’s version, yet for reading pāḷi, it is all there for me at my fingertips while relying on the pāḷi as the main source. I’m sure people criticise these translations and other translations as “distortions of dhamma”.
I fully agree that there is no perfect way. But that doesn’t mean that all options are equally bad or good.
Personally I really have to wonder if the person for whom LLM “pre-translations” can save hours and hours of time are really up to the task in the first place.
Different topic that I haven’t seen anyone address is the language difference between mulla/root texts and commentarial texts. If the language models are trained on root text translations (since there are almost no commentarial text translations available as people are eager to point out), does that mean that the MTs of the commentaries are being done based on the Pali of the root texts? Because that’s exactly the opposite of how things are supposed to work.
The Vinaya defines each key term in the Pātimokkha rules and provides examples of what is and isn’t covered by the rule. I think that’s a wonderful way to ensure that everyone is on the same page.
It’s not just about speed. One of the consistent feedback that Dharmamitra alpha testers gave us is that the tool gives them the feeling of not being alone, engaging in a dialog with something even if it just a machine, and that sort of ‘pair translation’ mindset means much less fatigue. So its not just about 10% faster, but you might also work on the material for one or two more hours than initially thought of.
I think the fun and playful aspect that interaction with machine learning systems has is easily neglected in these discussions.
A bit parallel to how people in the 2010s told us that growing up with digital dictionaries is inherently bad, and not having experienced the pain of flipping through Monier Williams by hand on a regular basis means you are less of a Sanskritist. Maybe…
I am very intrigued by the parallels that the reactions to the prospect of machine translation and AI technology in general on this forum have with how the catholic church reacted to Martin Luther’s translation of the bible into German. That’s another essay to be written.
In general, I am very positive about the democratization of access to the material via machine translation, especially into new languages. At some point in the not-so-distant future and we will have the Buddhist discourses in all the major languages in the world. Isn’t that wonderful?
Fixing a few mistakes here and there is much faster than writing directly from scratch. Reading Pali is much easier than translating it . Deciding on word order , breaking up into sentences and phrases takes a lot of work. Furthermore you might have to insert words from the previous sentence to make clear. There are many ways to translate the same sentence. Often the battle of choosing which version you like best when all are correct probably eats the most time. For this reason there can be a 10x efficiency factor or more .
For something like the commentaries, besides the “background stories”, it is often like a secondary dictionary to define the terms so the meaning does not get lost in the context.
But if it’s so much work, then why should a LLM be trusted to do this? If this was an easy task, I might be more inclined to trust MT, but all the arguments for why it’s hard sound to me like good reasons to have a human doing all of it.
When we are talking about sacred text translation that is. If I need a translation of something like a product manual, I really wouldn’t care.
I never heard anyone say that. To me it just isn’t analogous. How you get to the word in the dictionary doesn’t really matter. I do wonder, though, if the ease of looking up Pali words using digital dictionaries doesn’t make the learner lazy to actually memorize words. I know I’m lazy.
I think of all the things I’ve read in all the threads on this topic, this makes me the most sad. With all the tools of connecting humans to each other it’s too bad that people can’t actually work together on these things. Or is it maybe difficult to find another human we agree with? I don’t know.
It’s often interested me that Bible translations are almost exclusively done by teams (at least all the mainstream ones) and Sutta translations are almost exclusively done by individuals, at least into English.
I heard that a lot, the two key arguments being 1) you see the context of the word 2) since looking things up is hard, your memory will be better if you don’t use the digital tools.
I don’t think that dichotomy is really true. Buddhist texts have traditionally been translated by large teams first into Chinese and later into Tibetan. The bible, on the other hand, was prominently translated by individuals (Jerome, Wycliffe, Luther etc.) and the team-efforts are perhaps are more modern artefact, but also because the field of theology now is much larger. Looking at Japan, there are group efforts to edit and translate Buddhist texts (i.e. Sravakabhumi study group in Tokyo, MSA study group in Kyoto etc.). Perhaps the sole lonely translator is a theme that reappears when it comes to the transmission of Buddhist teachings to the west, because the field is small and people seriously interested in the texts are few. Notable exception is the Tibetan tradition that manages to entertain the largest translation project in the western Buddhist world (84000).
Indeed, it’s not clearly defined. But generally there are accessibility guidelines that can be used. Text to speech is the most obvious case I can think of, but I also think we should be listening to what people say they need.
Sure.
I don’t think so. But anyway, that can be done client side, so it shouldn’t be our concern.
I cannot confirm this from my own experience. I’ve tried with a pre-translation a couple of times and found editing that takes me no less time than doing it from scratch. But that’s perhaps simply my own way, and I know other translators feel differently about this.
And to be clear, it doesn’t matter for me whether the pre-translation is done by a machine or a human. I was once asked to complete translating a text that had been started by another translator, and I simply felt incapable to write in another person’s style, but at the same time I wanted to honor their work as much as possible while still delivering a consistent text. I think I’ve spent much more time with this struggle than I would have spent doing the entire translation on my own. But, as I said, that seems to be just me.
Let me still express my deep admiration for your ability of sincerely letting go. I know how much effort and love you have put into these translations, and this valuable work will leave its trace in your heart, no matter whether the result is still available or not.
And from the discussions we had when you came up with translation questions I could see that you had the exact same considerations as I also had, and often at the same passages. That was fun for me to see as well! So I think a translator’s mind works in similar ways, no matter into which language they are translating, and even if the target language is not the native language.
I am truly thankful for the opportunity of having glimpses into another translator’s struggles and insights!
How can we tell the difference? They all have human names. Is it the emoji? That hardly seems unmistakable. It’s also not clear how fast, slow, and English are exclusive to each other, but maybe I’m being picky.