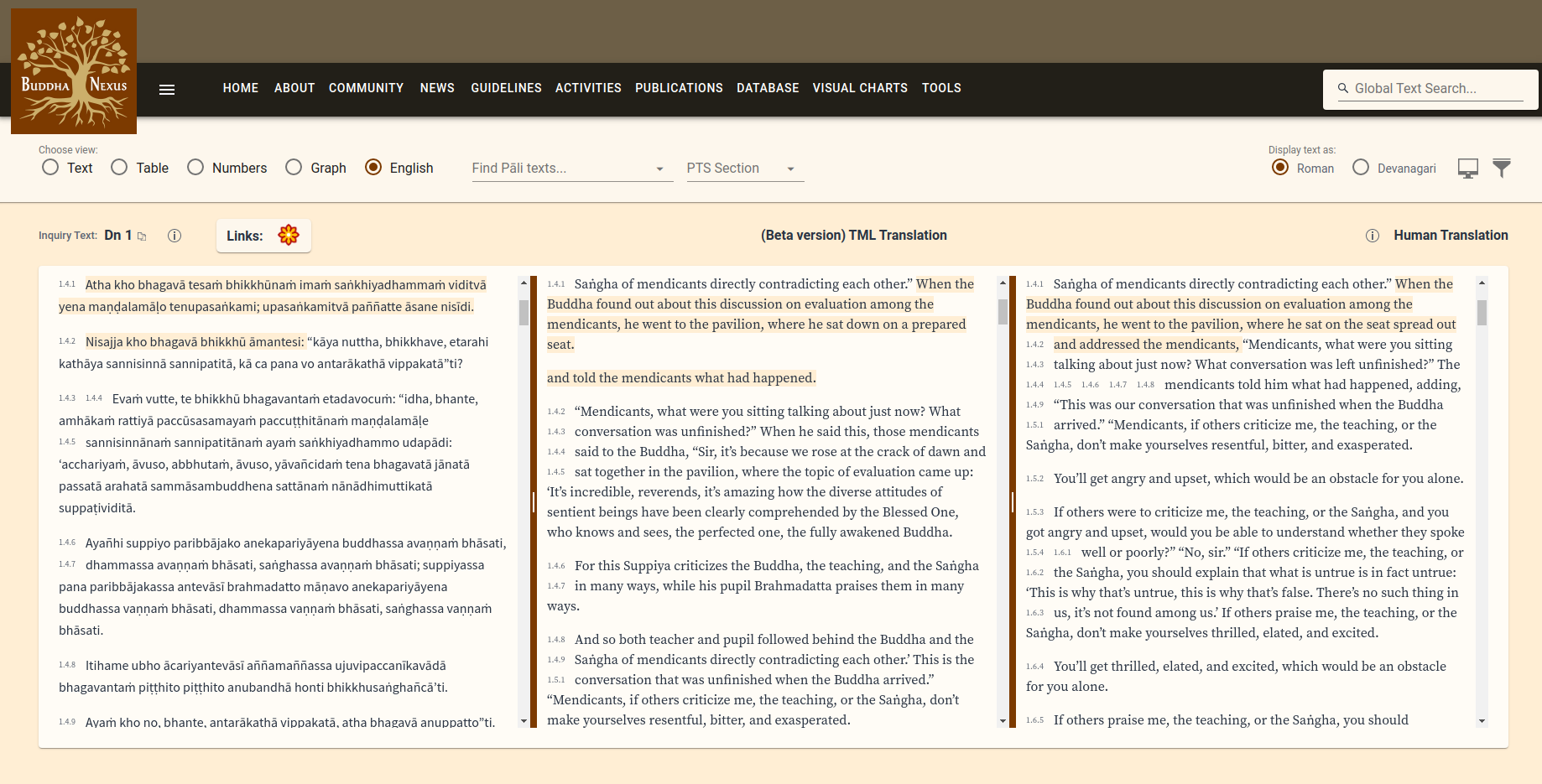
Just to clarify the details, the repo GitHub - BuddhaNexus/segmented-pali: Segmented files for pali. These are the input files for the Buddhanexus neural network holds all the inputfiles in segmented form in the directory inputfiles and use the exact same filenames as the VRI here: CSCD Tipitaka (Roman)
So the Brahmajālasuttavaṇṇanā, the first part of the Aṭṭhakathā suttas, the original filename is s0101a.att1.xml.
<p rend="chapter">1. Brahmajālasuttavaṇṇanā</p>
<p rend="subhead">Paribbājakakathāvaṇṇanā</p>
<p rend="bodytext">Imissā <pb ed="P" n="1.0026" /><pb ed="V" n="1.0027" /><pb ed="M" n="1.0027" /> paṭhamamahāsaṅgītiyā vattamānāya vinayasaṅgahāvasāne suttantapiṭake ādinikāyassa ādisuttaṃ brahmajālaṃ pucchantena āyasmatā mahākassapena – ‘‘brahmajālaṃ, āvuso ānanda, kattha bhāsita’’nti, evamādivuttavacanapariyosāne yattha ca bhāsitaṃ, yañcārabbha bhāsitaṃ, taṃ sabbaṃ pakāsento āyasmā ānando evaṃ me sutantiādimāha. Tena vuttaṃ ‘‘brahmajālassāpi evaṃ me sutantiādikaṃ āyasmatā ānandena paṭhamamahāsaṅgītikāle vuttaṃ nidānamādī’’ti.</p>
<p rend="bodytext" n="1"><hi rend="paranum">1</hi><hi rend="dot">.</hi> Tattha <hi rend="bold">eva</hi>nti nipātapadaṃ. <hi rend="bold">Me</hi>tiādīni nāmapadāni. <hi rend="bold">Paṭipanno hotī</hi>ti ettha <hi rend="bold">paṭī</hi>ti upasaggapadaṃ, <hi rend="bold">hotī</hi>ti ākhyātapadanti. Iminā tāva nayena padavibhāgo veditabbo.</p>
etc.
The filename in inputfiles is then atk-s0101a1_root-pli-ms.json and in it the segments follow the XML structure of the original files. Segment numbers are consecutive. The numbers like <pb ed="P" n="1.0026" /><pb ed="V" n="1.0027" /><pb ed="M" n="1.0027" /> have not been used but can be easily extracted in any way that is desirable.
"atk-s0101a1:0": "1. Brahmajālasuttavaṇṇanā",
"atk-s0101a1:1": "Paribbājakakathāvaṇṇanā",
"atk-s0101a1:2": "Imissā paṭhamamahāsaṅgītiyā vattamānāya vinayasaṅgahāvasāne suttantapiṭake ādinikāyassa ādisuttaṁ brahmajālaṁ pucchantena āyasmatā mahākassapena – ‘‘brahmajālaṁ, āvuso ānanda, kattha bhāsita’’nti, evamādivuttavacanapariyosāne yattha ca bhāsitaṁ, yañcārabbha bhāsitaṁ, taṁ sabbaṁ pakāsento āyasmā ānando evaṁ me sutantiādimāha. Tena vuttaṁ ‘‘brahmajālassāpi evaṁ me sutantiādikaṁ āyasmatā ānandena paṭhamamahāsaṅgītikāle vuttaṁ nidānamādī’’ti.",
"atk-s0101a1:3": "1. Tattha evanti nipātapadaṁ. Metiādīni nāmapadāni. Paṭipanno hotīti ettha paṭīti upasaggapadaṁ, hotīti ākhyātapadanti. Iminā tāva nayena padavibhāgo veditabbo.",
etc.
Because for the TML these segments are too long, they are split in the directory inputfiles_cut_segments_for_TML_v1:
"atk-s0101a1:0_0": "1. Brahmajālasuttavaṇṇanā",
"atk-s0101a1:1_0": "Paribbājakakathāvaṇṇanā",
"atk-s0101a1:2_0": "Imissā paṭhamamahāsaṅgītiyā vattamānāya vinayasaṅgahāvasāne suttantapiṭake ādinikāyassa ādisuttaṁ brahmajālaṁ pucchantena āyasmatā mahākassapena –",
"atk-s0101a1:2_1": "‘‘brahmajālaṁ, āvuso ānanda, kattha bhāsita’’nti, evamādivuttavacanapariyosāne yattha ca bhāsitaṁ, yañcārabbha bhāsitaṁ, taṁ sabbaṁ pakāsento āyasmā ānando evaṁ me sutantiādimāha.",
"atk-s0101a1:2_2": "Tena vuttaṁ ‘‘brahmajālassāpi evaṁ me sutantiādikaṁ āyasmatā ānandena paṭhamamahāsaṅgītikāle vuttaṁ nidānamādī’’ti.",
"atk-s0101a1:3_0": "1.",
"atk-s0101a1:3_1": "Tattha evanti nipātapadaṁ.",
"atk-s0101a1:3_2": "Metiādīni nāmapadāni.",
"atk-s0101a1:3_3": "Paṭipanno hotīti ettha paṭīti upasaggapadaṁ, hotīti ākhyātapadanti.",
"atk-s0101a1:3_4": "Iminā tāva nayena padavibhāgo veditabbo.",
etc.
The TML output files use that same structure in the directory outputfiles_TML_v1 with filename ai-atk-s0101a1.json:
"ai-atk-s0101a1:0_0": "1. Brahmajālasuttavaṇṇanā",
"ai-atk-s0101a1:1_0": "Talk on Wanderers",
"ai-atk-s0101a1:2_0": "Because of this exposition of the teaching on the Great Wood, in accordance with the Monastic Law, and properly resolved.",
"ai-atk-s0101a1:2_1": "‘Reverend Ānanda, the Brahmā realm is spoken to by me! That’s what I said.’",
"ai-atk-s0101a1:2_2": "That is what I said.’",
"ai-atk-s0101a1:3_0": "1.",
"ai-atk-s0101a1:3_1": "and the doing of the performing of all states.",
"ai-atk-s0101a1:3_2": "my baby is called ‘the step.’",
"ai-atk-s0101a1:3_3": "And here they’re practicing to win in this way.",
"ai-atk-s0101a1:3_4": "This is the extent of this penetration.",
etc.
(Note that headings are not translated.)
But like I said, the translation leaves much to be desired.
One improvement I see is that certain code is still in the inputtext for the TML and taking that out will no doubt improve the results.
UPDATE: I made a new directory inputfiles_cut_segments_for_Aijato_next_run that removes some of the code that is probably one cause of problems so this can be used for a next run of the TML This also takes care of some of the wrong quotemarks.