The Pali IAST transliteration system we use today was standardized at the Tenth International Congress of Orientalists in Geneva, 1894.
In 2001, it was adapted with minor emendations to form ISO 15919.
It is always said that one of the key differences between the two is the representation of anusvāra, which figures prominently in Pali as the nazalization at the end of words. IAST uses ṃ underdot for anusvāra, while ISO 15919 uses ṁ overdot.
Thus are the battle lines drawn.
Most Pali editions of the 20th century use ṃ underdot. The ISO standards committee used ṁ because of compatibility with other Indic languages. It is also more rational, as ṅ is the same sound as ṁ, but ṇ is a completely different sound. In fact, the superiority of ṁ seems so obvious it is surprising it was not recognized by the Congress.
Or was it? Thanks to the Internet Archive, you can read the proposal for the Geneva Congress by James Burgess, one of the participating scholars.
On page 30, Burgess states:
For the anusvāra, m with a dot above or below is the alternative. The dot below is distinctive of the linguals [i.e. the retroflex such as ṇ], but if placed above it distinguishes this sound from them, while it corresponds in position to the devanāgarī sign, and being already largely in use, ṁ is distinctly preferable.
And in his table for the transliteration, he does indeed use ṁ.
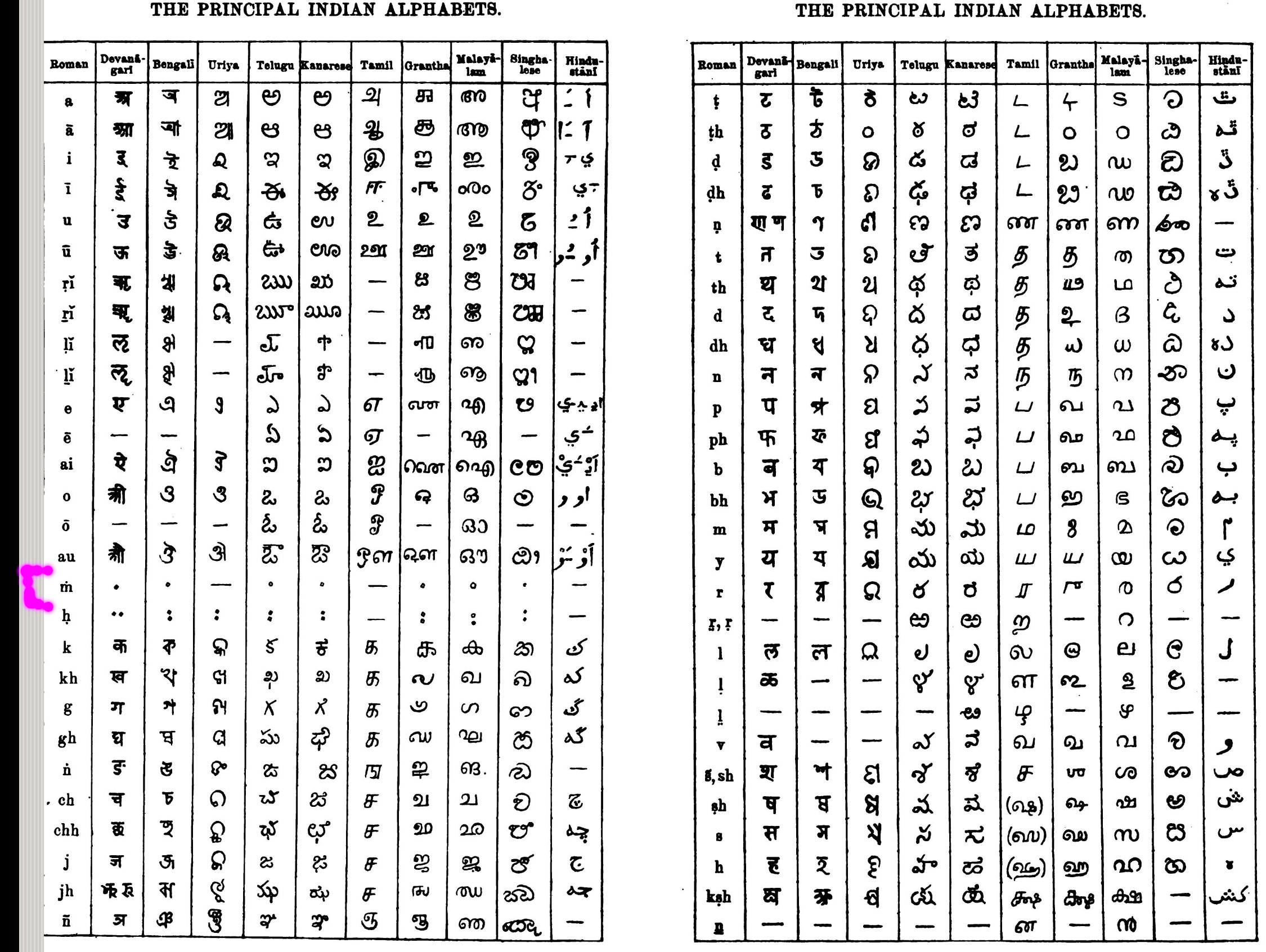
So the proposal used ṁ, arguing that it is “distinctly preferable”. But what of the official notice of the proceedings? The original French notice is available here.
This official committee report from the Congress also has ṁ for anusvāra (pg. 6).
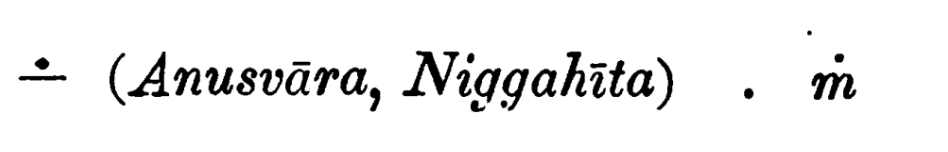
A note discussing the report by the leading French Indologist Emile Senart likewise uses ṁ with overdot (pg. 13).

This report is also available in English translation.
Here we also find the main table uses ṁ overdot (pg. 881).

And the translation of Senart’s note is the same (pg. 887).

Subsequently, the Royal Asiatic Society published a Transliteration Report of 1896 which summarized the proceedings of the Congress.
This too also gave ṁ for anusvāra, without mentioning ṃ (pg. 6).
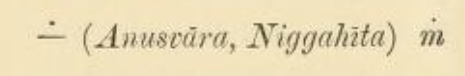
It also provides examples of Pali and Sanskrit text using ṁ for anusvāra (pg. 11).

Thus the proposed ṁ overdot for anusvāra, being well reasoned, was adopted by the Transliteration Committee at the Geneva Congress of 1894 and is recorded consistently in all the contemporary official publications. It is therefore the official IAST standard.
Later, ṃ became widely used in publications, and at some point it was assumed this was the recommendation of the Congress. I have no idea why; perhaps it was simply that the character sets available for printers had ṃ.






{kind=link}