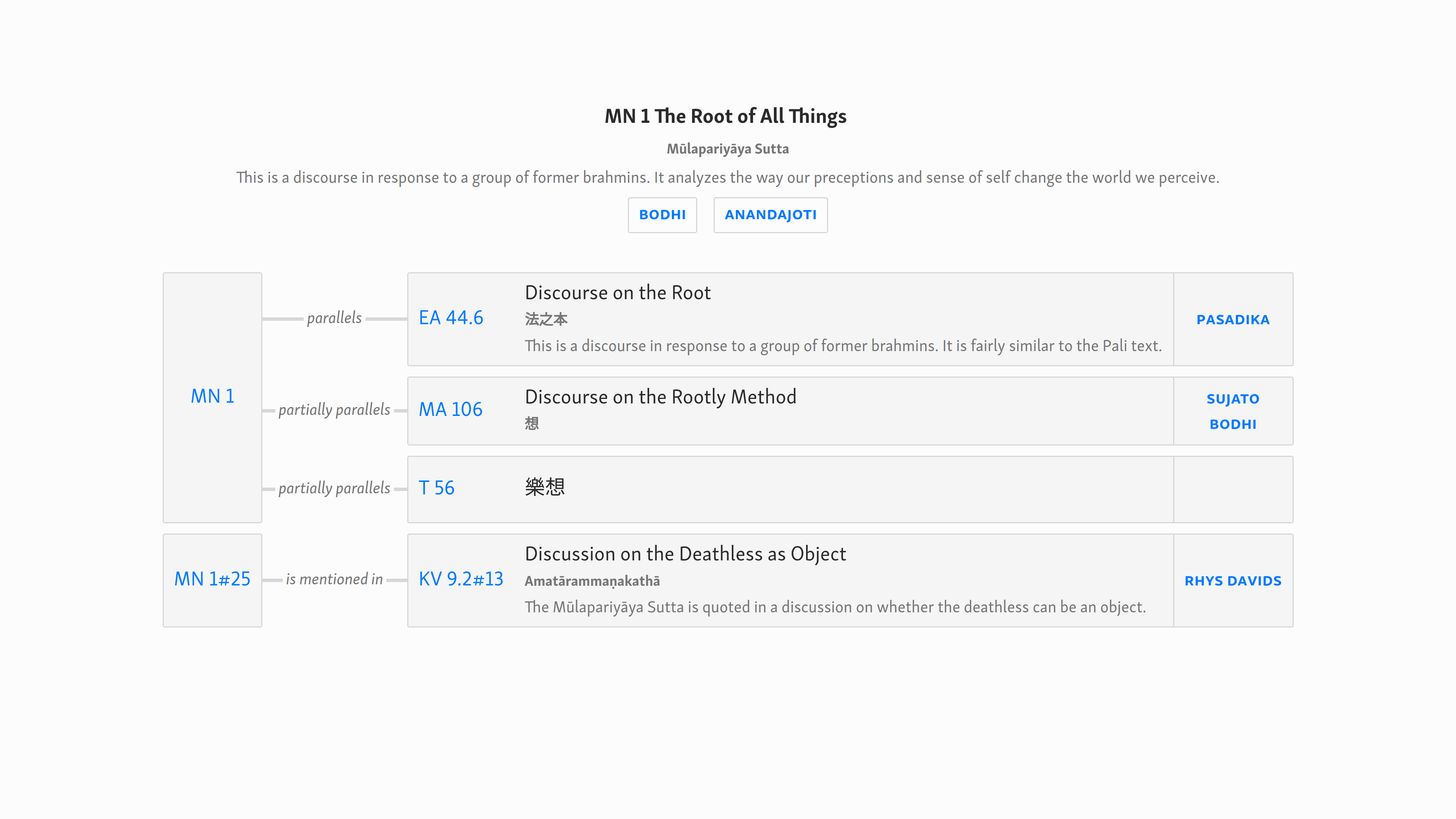
In SuttaCentral we currently have:
mn1 parallels ea44.6
mn1 ~parallels ma106
mn1 ~parallels t56
mn1#25 is mentioned in kv9.2#13
How might we display this in a fuller form? Rather than sticking too closely to the table view, we could move closer to an information design such as a flow chart, mind map, etc. Essentially, we are showing “things” and “relations between things”, so why not represent that visually? But we shouldn’t move too far in that direction, as we still want to keep the information vertically aligned and quickly scan-able, like a table. We can keep the information structured as a table and use a little CSS to highlight the connections.
Perhaps something like this.

And here’s the code: details_mockup.html.zip (1.5 KB)
(Note that I’ve changed this a few times, now the latest changes are included in this post.)
Some salient points in the design;
- I’ve removed the “language” column.
- The first column is the “root” text ID. Instead of having multiple entries, they are merged (using “rowspan”).
- Each of the “things” is included in a box. The point of this is to establish visually that everything to the right of the second ID is referring to the same “thing”.
- Compared with the current design, there’s a clearer visual hierarchy. Secondary information is smaller and greyed out.
- The “alternative” reference details are moved from the ID column to the Vol/Page column, again to clarify the visual hierarchy.
- The canonical IDs are emphasized by being in link color.
- Italicize the “relation” text; this emphasizes that one “runs on to” the next, and it’s also a bit more compact.
- Use a joiner to connect the boxes, as in flow charts, etc.
- I’ve removed the
<th>row altogether, I don’t think it’s necessary. Instead use title attributes to clarify, making them as explicit and clear as possible, especially for newbies. - This design uses Skolar Sans, which is probably better for the tables.
- Some design cues have been taken from material design. Especially treating all the info on the secondary text as one set, analogous to the “cards” of material design. This can be followed more precisely by using shadows; but they’re tricky to handle in this context, so I stick with borders.
Overall I’m pretty happy with this, I think it’s clearer than the current design, it shows the relationships much more naturally.