@Blake - When trying to go the the page Abhidhamma - Paṭṭhāna (which should be https://suttacentral.net/pt), I get instead the draft Portuguese internationalized version of the website.
Maybe you can remove the Portuguese site for now until it is clear if we are going to Node.JS or not.
It is an error that the language and the division UIDs collide. We need @sujato to invent a new UID for the Paṭṭhāna.
I wrote a quick modification to the IMM to check for colliding uids and it occurs about a dozen times:
UID: sv is used for <Language>: "Svenska" and <Sect>: "Sarvāstivāda"
UID: pt is used for <Division>: "Paṭṭhāna" and <Language>: "Português"
UID: lzh-mi-vs is used for <Sutta>: "調伏法 (Regulations)" and <Division>: "Saṁyutta"
UID: sht1 is used for <Sutta>: "" and <Subdivision>: "SHT i – ed. W. Clawiter, L. Holzmann, E. Waldschmidt 1965"
UID: sht2 is used for <Sutta>: "" and <Subdivision>: "SHT ii – ed. W. Clawiter, L. Holzmann, E. Waldschmidt 1968"
UID: sht3 is used for <Sutta>: "" and <Subdivision>: "SHT iii – ed. W. Clawiter, L. Holzmann, E. Waldschmidt 1971"
UID: sht4 is used for <Sutta>: "" and <Subdivision>: "SHT iv – ed. L. Sander, E. Waldschmidt 1980"
UID: sht5 is used for <Sutta>: "" and <Subdivision>: "SHT v – ed. L. Sander, E. Waldschmidt 1985"
UID: sht6 is used for <Sutta>: "" and <Subdivision>: "SHT vi – ed. H. Bechert, K. Wille 1989"
UID: sht7 is used for <Sutta>: "" and <Subdivision>: "SHT vii – ed. H. Bechert, K. Wille 1995"
UID: sht8 is used for <Sutta>: "" and <Subdivision>: "SHT viii – ed. H. Bechert, K. Wille 2000"
UID: sht9 is used for <Sutta>: "" and <Subdivision>: "SHT ix – ed. H. Bechert, K. Wille 2004"
UID: sht10 is used for <Sutta>: "" and <Subdivision>: "SHT x – ed. K. Wille 2008"
UID: skt-lo-bi-vb-nidana is used for <Sutta>: "Mahāprajāpati Gautamī and the garudhammas" and <Division>: "Nidāna"
I’ve pushed the collision-scanning code into master branch. Note that at the moment it only prints an error message. But once these issues have been fixed it should be changed to raising an exception (aborting) so that the collision needs to be fixed immediately.
Umm, this is tricky. We could use “pat”, but it is a very common initial sequence, we have patidesaniya, patimokkha, patthana, and patisambhidamagga, and it gets pretty unclear which is which.
The PTS abbreviation for Patthana is Paṭṭh, which is ruled out for us because it has diacriticals. We could use “Patth”, perhaps. But this is getting pretty long.
Or—warning, heresy to follow!—perhaps we could just not abbreviate it. Use “patthana”. It’s not much longer than patth, and there’s no disambiguation problems. What say you?
And how about sv for Sarvāstivāda and Swedish? Not sure if that will ever clash because “sv” for Sarvāstivāda is not being used on it’s own (I think). But it might be good practice to avoid such things altogether.
I’m not sure what sutta “sht” is supposed to refer to.
Good point, we really should avoid duplicating ID strings. For sv we could either say Swedish=“swe”, or Sarvastivada=“sarv”. probably the latter, I guess, since it’s the most common abbreviation used anyway.
Sht is on our awesome abbreviations page: Sanskrithandschriften aus den Turfanfunden
I would keep sv for Swedish. We are using ISO language codes for all our languages and I think we should stick to that.
Yes, I agree, so in future if we have a similar problem we change the abbreviation for the text. So far we have:
- it --> Iti for Itivuttaka
- sv --> sarv for Sarvastivada
- pt --> patthana for Patthana
Let’s hope there’s not too many more!
I will make the changes if that is OK with you @Blake. It will help me to get a feel for the whole structure of the site.
I have changed pt and sv (Iti was already Itivuttaka).
Just wondering if sht needs to be changed as well because now it has suttas sht1 to sht11 in subdivision sht1, suttas sht12 to sht 15 in subdivision sht2 …
Yes, this is a complex problem.
What we have here is a large number of manuscript fragments, which have been collated to occur as parts of a “sutta”. Now, the simplest “canonical” form is to refer to each fragment as an SHT number. These are the numbers that occur as “vol/page” in sutta.csv. Since this form is the generally accepted use, we should keep it. (Thanks to John Nishinaga, we have a nice little script that creates links for each of these to the manuscript images. Actually, it would be really nice to scrape these and present them locally, but that’s a job for another day.)
Then these are all collected together into a “sutta”. This is, of course, not a full sutta, just a collection of fragments that have been identified as belonging to one sutta.
These are the numbers presented under “uid” in sutta.csv.
Finally, we have the subdivisions, which represent the collection of identified sutta fragments published in one edition of the SHT series. In other words, this is an entirely arbitrary structure: it has no meaning in relation to the texts, only to their publication history. These appear in the subdivision_uid column of sutta.csv, and the relevant explanations in subdivision.csv. These are conventionally represented with Roman numerals.
Currently we don’t present this information well. The ID column in fact just says “SHT”, which is very wrong: the whole point of the ID column is to give a unique, linkable ID for every text.
So how to proceed?
We should stick to our usual SC policy, and treat the sutta as the fundamental entity. But then, we can’t call that simply “SHT x”, because that’s used for the fragments. So we’d need to distinguish the URL in some way. How about:
sht-sutta1 = the first SHT sutta (Which as an acronym expands to “SHT sutta 1”)
sht-sutta1.3 = fragment 3, which occurs in the first sutta, and is equivalent to:
SHT 3
or something like that.
pauses for lunch
continues
I’ve rethought the following, so ignore this for now, but I leave it in case my revised plan doesn’t work!
For the Volume, we could adopt a similar method. Eschewing Roman Numerals (because they are silly) we would have:
- sht-vol1 (Which as an acronym expands to “SHT vol 1”)
- sht-vol2
And so on. The SHT fragment numbers remain as they are (but these are not used as URLs on SC).
So for the first entry in sutta.csv we have:
name,uid,subdivision_uid,vagga_number,number_in_vagga,language,acronym,volpage,biblio_uid
,sht-sutta1,sht-vol1,,,skt,SHT sutta 1,"SHT 3, 768, 685 (94–119V), 690, 916, 165.41, 412.34, 1592, 2009, 2032, 2033, 2034, 2172, 2446, 2995; also cf. ix p. 393ff",sht
If we adopt this approach, there will have to be a difference in the logic handling these as compare with the other subdivisions. Normally we include each level as part of the URL, and the URL consequently lengthens as we navigate through division (/an), subdivision (/an4), and sutta (/an4.35). But that would be weird and clumsy in this case.
Better would be to go: division (/sht), subdivision (/sht-vol1), sutta (/sht-sutta1).
(Currently the navigation craps out when the sutta number and subdivision number are the same, woops!)
From here is my new idea
I just realized that we’re making this too complicated by using subdivisions. How about we eliminate subdivisions and just have one SHT division: there’s not too much information, which is the only reason we have subdivisions. The Volume information can be recorded as vaggas, not as subdivisions, so we keep the info, but it has no URL and no impact on navigation.
name,uid,subdivision_uid,vagga_number,number_in_vagga,language,acronym,volpage,biblio_uid
,sht-sutta1,,1,,skt,SHT sutta 1,"SHT 3, 768, 685 (94–119V), 690, 916, 165.41, 412.34, 1592, 2009, 2032, 2033, 2034, 2172, 2446, 2995; also cf. ix p. 393ff",sht
In vagga.csv we would have:
subdivision_uid,number,name
sht,1,SHT vol. 1—ed. W. Clawiter, L. Holzmann, E. Waldschmidt 1965
Note that the first column here is nisnamed, it includes divisions.
We remove the info from subdivisions.csv, et voila! Relax with a nice espresso.
Oh, and check that we haven’t completely destroyed everything. That would be nice.
And BTW, while I’m at it, I just noticed that uid_expansion.csv still has the old IDs (unless this has been recently fixed), so should be corrected.
Just to rectify a few things:
Corrected: These are the numbers presented under “uid” in sutta.csv
Corrected: These appear in the “subdivision_uid” column of sutta.csv
sutta.csv:
name,uid,subdivision_uid,vagga_number,number_in_vagga,language,acronym,volpage,biblio_uid
,sht2,sht1,skt,SHT,“SHT 160c, 1561”,sht
There is a comma before the first entry so the “name” field is blank.
So in this example:
sht2 = uid
sht1 = subdivision_uid
SHT = acronym
“SHT 160c, 1561” = volpage
sht = biblio_uid
So in this example, you suggest to change this particular entry to:
,sht-sutta2,sht1,skt,SHT Sutta 1.2,“SHT 160c, 1561”,sht
Or something like that???
See my new comment, I have corrected the things you mention, have a look at my new approach.
Do you mean patthana (instead of pt) and sarv (instead of sv)? That was changed already or am I missing something here …
Will have a look at the rest and get back to you.
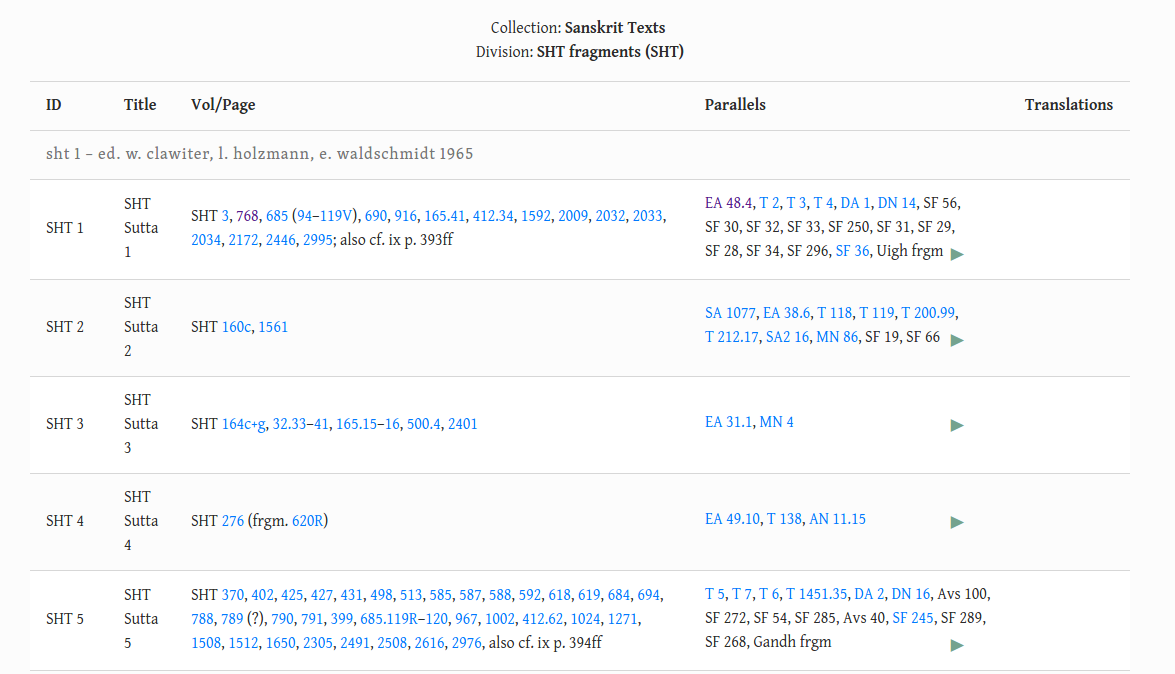
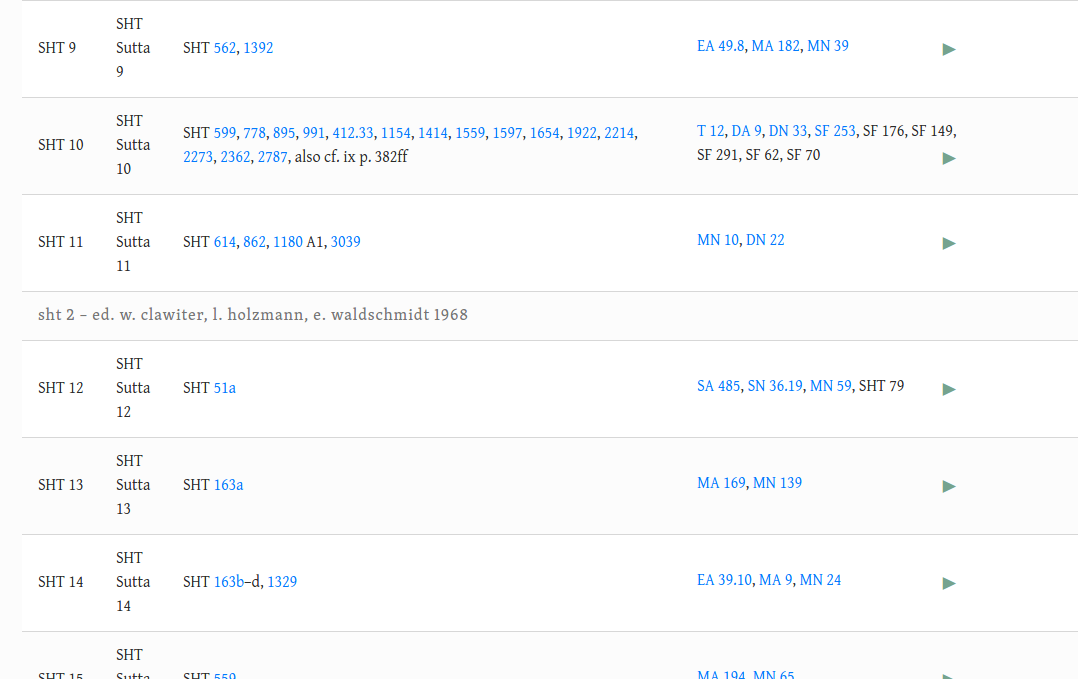
@Sujato - herewith a screenshot from my local development to show what it looks like if you make it into Vagga’s instead of subdivisions (as it is now in SC). If you want I can upload this to staging if nobody is using that at the moment, but I think the screenshot basically gives all the information needed.
I made it slightly different from your suggestion so as to make sure the various csv files would correspond but the basic idea is the same.
I think we can probably take the “Title” part (i.e. SHT Sutta 1) out.
Hi great, thanks.
What’s in the title column should be in the ID column.
Then, yes, the Title can be empty. Although, it might be nice to include the actual Sutta title, as found in the Pali text. For example, SHT sutta 1 = DN 14, so the title would be Mahāpadāna. This would be nice, but a little dubious, since we have no way of knowing whether the actual manuscript used such a title. Still, if it could be done.
We should definitely preview and test on staging first.
What is in the ID column is the Acronym from sutta.csv. The uid in sutta.csv is sht1 in this case, which is not visible but it creates the links so that has to stay.
I basically used the same system as with the DN, which has no subdivisions either. There the Title is the actual Sutta name (Brahmajāla). The ID is DN 1.
So we can deviate from this system slightly and use the Acronym of “SHT Sutta 1” instead and keep the Title blank or put something else in there. That should not be a problem.
That’s what I have in my original example.
We need to make sure that things of the form “SHT 2” are used only for the fragments. For the sutta, it must always be “SHT Sutta 2” as expended acronym, or as URL-friendly ID “sht-sutta2”
The slight difference from your example is that there are Vaggas and sutta numbers within Vaggas:
,sht2,sht,1,2,skt,SHT Sutta 2,“SHT 160c, 1561”,sht
This makes sure that the the actual suttas keep their original number (sht2) which are used in the python files so I don’t want to start messing with that. These numbers are only used for the suttas and nothing else so everything should work OK.
The problem was that these numbers were used both for suttas and subdivisions and that problem has now been removed.
I will put it on staging when I get back from Pindapata …
It’s on staging now. Seems to work fine. If there are no objections, I will merge.
https://staging.suttacentral.net/sht