Hi Suvira,
Yes, that’s how it’s done in most Pali schools in Thailand. Prince Vajirañanavarorasa, the late 19th century creator of modern Thai monastic education, basically modelled his approach to teaching Pali on the way that he’d been taught Latin by his British tutors (who were reportedly very hard taskmasters). And so as in Victorian Latin teaching, all the tables of declensions, conjugations, prefixes, suffixes, indeclinables, etc. have to be systematically memorised.
This, by the way, is actually considered the easy way of learning Pali grammar, and is regarded very sniffily by visiting Burmese monks and by the handful of Thai Pali schools that have adopted the Burmese pariyatti system.
In the Burmese approach you start by memorising the 673 suttas (in the sense of “aphoristic rules”) that make up Kaccayana’s Pali grammar. As you’re memorising these (which is mostly done as homework and takes about six months) your teacher will spend the class time going through one of the commentaries to Kaccāyana, usually Buddhappiya’s Padarupasiddhi. (The commentary is essential since the aphorisms are even more succinct and compressed than those in the Abhidhammatthsangaha).
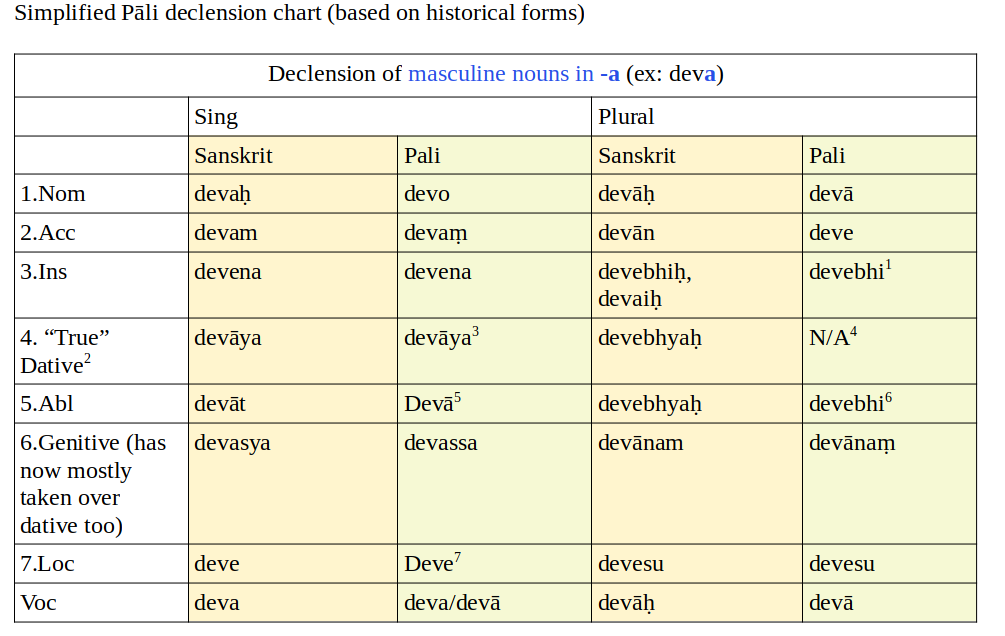
So, let’s take noun and adjective declensions, for example.
You start by memorising aphorism 55:
55. Si yo, aṃ yo, nā hi, sa naṃ, smā hi, sa naṃ, smiṃ su.
Kā ca pana tāyo vibhattiyo? Si, yo iti paṭhamā, aṃ, yoiti dutiyā, nā hi iti tatiyā, sa, naṃiti catutthī, smā, hi iti pañcamī, sa, naṃ iti chaṭṭhī, smiṃ, su iti sattamī.
This gives you the names of the seven cases along with fourteen placeholder forms (the text in bold) representing their inflectional endings.
Then you have to memorise all the rules for converting the placeholder form into the form that’s actually required, depending on the gender, number and case of the noun in question. Each rule is derived from some later aphorism. And so you sit in class reciting like this (I’m translating from Thai):
Masculine nouns in -a. Purisa, “man”.
Nominative: Change si to o: puriso. Change yo to ā, purisā.
Accusative: aṃ remains aṃ, -a in purisa is elided: purisaṃ. Change yo to e: purise.
Instrumental: rassa the ā in nā, a is gunated to e: purisena. Hi remains hi, a is gunated to e: purisehi.
Dative: change sa to ya, dīgha the ā: purisāya. Naṃ remains naṃ, dīgha the ā: purisānaṃ.
Etc.
Later, when you get to aphorism 99, you learn that the placeholders smā, hi and smiṃ can change to mhā, bhi and mhi in all genders:
99. Smāhismiṃnaṃ-mhābhimhivā.
Sabbato liṅgato smāhismiṃ iccetesaṃ mhābhimhiiccete ādesā honti vā yathāsaṅkhyaṃ.
Purisamhā, purisasmā, purisebhi, purisehi, purisamhi, purisasmiṃ.
But it’s not until aphorism 108 that you learn that locative smiṃ can become e and ablative smā can become ā:
108. Smāsmiṃnaṃvā.
Tasmā akārato sabbesaṃ smāsmiṃiccetesaṃ ā e ādesā honti vā yathāsaṅkhyaṃ.
Purisā , purisasmā, purise, purisasmiṃ.
So, as you can see, it’s a slow, cumbrous and dull-as-ditchwater way of learning the grammar, even if it does enjoy a certain advantage when it comes to thoroughness.
When I was at the Pali school at Wat Benchamabophitr in Bangkok we used Vajirañanavarorasa’s Gradgrindian Latin-teaching system. I don’t recall needing to take a breath when reciting the noun declensions. One inhalation sufficed to get me from puriso to purisesu.
With verb conjugations, we’d recite each verb in its parassapada and attanopada forms for each of the eight tenses and take a breath after every second tense. Like this:
vattamānā and pancamī.

sattami and parokkhā
hiyyattani and ajjattanī.
bhavissantī and kālātipatti.
Well, that gave me a nice excuse to use the lungs emoji for the first time ever.
Best wishes,
Dhammanando