Thanks largely to the hard work of @vimala we have more languages available on the Pali Lookup, such as German and now Dutch.
I have just updated the interface for choosing the popup language. It was a little bit, well, wonky, almost broken maybe for non-english. Now it is no longer biased towards english except that english is the default language. If you have set a preferred translation language and that language is available then it will be used preferably. Once you’ve selected a language that language will be remembered.
Hopefully the controls are more intuitive now, in how you choose the language and activate the dictionary.
Thanks @blake.
Unfortunately both the German and Dutch dictionaries only have around 1300 words. This is not very much so you will find that it does not know most words.
Ayya Vimalanyani is working to improve the German dictionary but if there is anybody who would like to contribute, either on the Dutch or the German dictionary, please let me know.
You know I was thinking we could use Google Translate to do the preliminary translation. I have a feeling that these days Google Translate really is better than nothing, especially when one of the languages is english.
I did a little test with a few words that appear in all the dictionaries we have. I compared the pali - english with pali-dutch and pali-german and with their english-dutch/german counterparts from both Google and Bing.
The result you can find in https://drive.google.com/file/d/0B9X72SQelXj7Y21hQl96NWZHaTA/view?usp=sharing
The preliminary conclusions:
Google does far better than Bing but sometimes also has the wrong translation entirely. But most of the time it’s fine.
The Dutch and German dictionaries on SC are more extensive and clear about the meaning of the pali words, but therewith also far longer, which might not be necessarily what we want.
However, there are a few big advantages to using Google from the English:
Of course it would give immediate access to many languages and going from the PTS dictionary, also to the translation of 20.000 pali words.
When we change a meaning in the English dictionary (for instance changing samadhi from concentration to silence) it immediately changes everywhere and you don’t need to worry about different interpretations in different dictionaries.
I noticed that different pali to language dictionaries sometimes use different forms (for inst. voc) of pali words and sometimes do not use the correct diacritical marks for the pali words. That means that the lookup tool will simply not find these words.
It would make the whole thing far more consistent.
It seems you basically agree with my verdict. That google is certainly not perfect, you know it’s machine translated, and don’t nessecarily expect it to be correct, but it actually is better than nothing (something which I couldn’t have said 5 years ago)
With 3) incorrect or variable diacriticals are actually very easy to fix using some slight fuzzy matching. I’ve done it before with the DPPN dictionary. You just take each word, see if it matches any word in the corpus, if there is no match, you then see if there’s a really good fuzzy match, and if there is, you assume that is the word it’s meant to be.
Note there are two approaches to using google. The first is you get a proper account and use their API, either on the fly or in bulk. The second is you just compile an HTML file and upload it to their translation server. The size limit is 1MB, meaning the pali dictionary can be uploaded as two chunks, this obviously only works as a bulk approach (if only because Google is pretty savvy about people exploiting their free web services, they’ll start throwing up captchas if they think they’re getting traffic from a script rather than a human. So you can get away with doing it manually, or perhaps the occasional request by machine, but you certainly can’t do it repeatedly in a short time span)
The advantage of either bulk approach is we send a precompiled dictionary to the user, and the lookup is then instant in their browser.
I would probably go with a bulk approach, where a google translated version is used as a fallback. That is, two dictionaries would be sent over the wire, the first is the human translated one, the second the google translated one. I already do something like this with the Chinese lookup, where a first dictionary is a Buddhist dictionary, and the second a generic one. The second dictionary is used as a fallback, and is marked as such.
Sounds good. So if I understand it correctly, you would be using the pali-language dictionary on SC first and if the word cannot be found in there (either direct or fuzzy), it does a google translate of the English from the pali-english dictionary. Sounds like a very good solution.
Just 2 questions:
Will the user know which translation method is used i.e. does he see a {translated by Google} tag in there somewhere?
If something changes in either our dictionar(y)(ies) or Google’s translations, does it automatically also update?
Just noticed that the English dictionary does not recognise the word bhikkhū (with diacritical mark on the u). It recognises it without the diacritical mark.
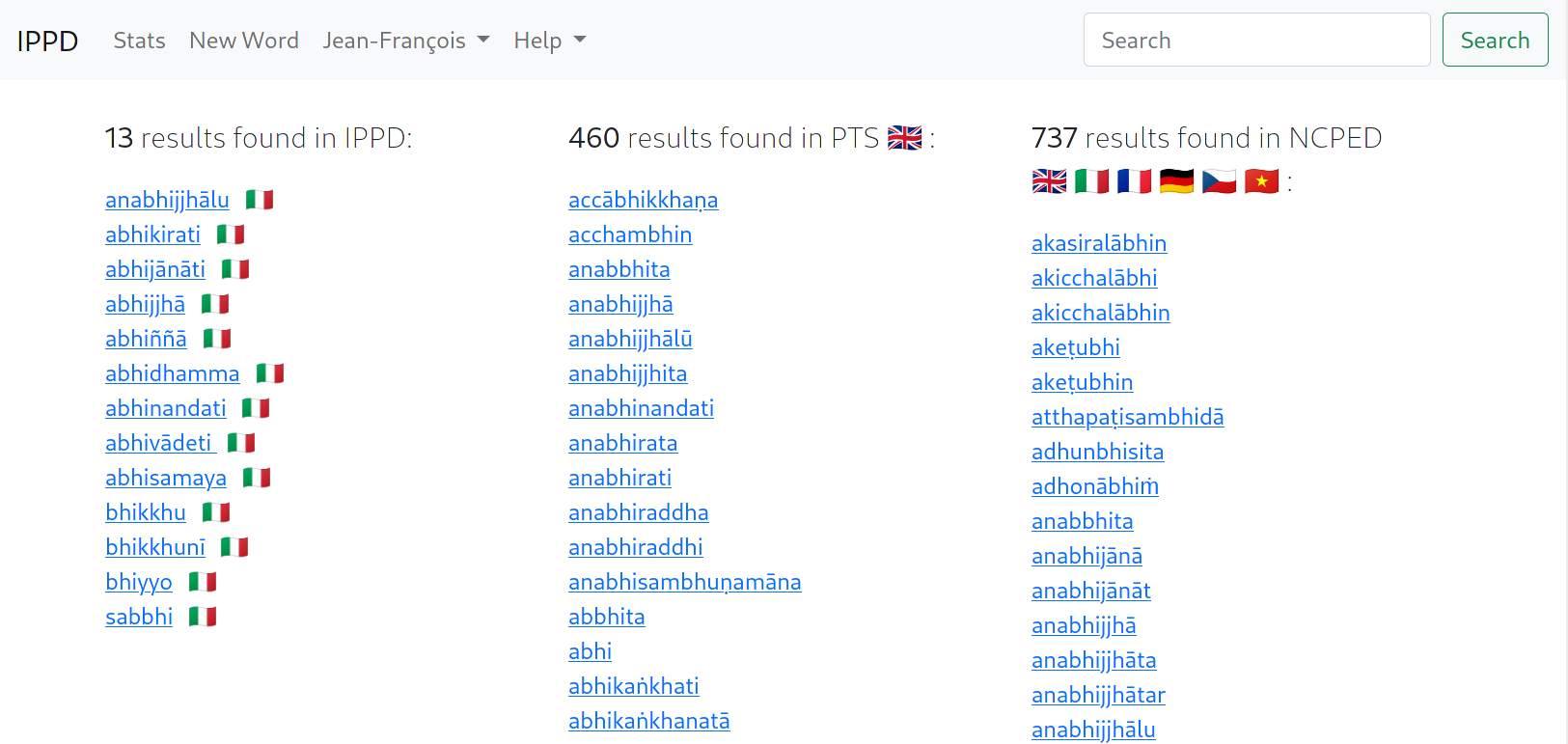
I don’t know it there is still interest in this, but I’m able to build machine-translated (google) versions of the " New Concise Pali English Dictionary". So far, I’ve made an Italian and a French version ; I can also do it for other languages if someone is interested !
Thank you very much for your work, @jromang, this is definitely helpful for many!
The German dictionary has disappeared from SuttaCentral altogether already for some years, I don’t know for which reason. Google translation is certainly better than no translation!
As making the Dhamma accessible for German speakers is what I am dedicated to I’d put in my vote for German here.
How does this work in practice? Are there any plans these files can be implemented into SuttaCentral so that users can access the dictionary entry via the lookup tool? The file you posted is certainly readable for a machine, but not so much for a human.
It has to be added to suttacentral, but I don’t know how ; also I don’t know if it has the required quality.
If you want to have a look, you can open it in Firefox, it should be a bit more readable (but still not usable).
I will add it to the IPPD too, maybe this week !
Better would of course be to be able to check it in a context with actual text and the possibility to compare with the English. But just from some random clicking around I’d say, if the costs of effort for implementing it are not excessively high, it’s definitely worth giving it a go.
Doesn’t have to be perfect, the English also isn’t perfect, but still a great help!
If we use it, we could still translate the explanatory terms of the dictionary, but that wouldn’t be too much work as they are probably not many.
“entry”, “grammar”, “definition”, “masculine”, etc.
That’s the goal of the IPPD I’ll import the german version of the NCPED, so if you want to contribute, there will be a good starting point. The tool should be ready in a few weeks. And I hope to export the improvements back to suttacentral !
I am excited! Really, building a dictionary with many thousand entries in just a couple of minutes is impressive! With all the apprehension I have towards Google—but for this they deserve a big SADHU!!!
And you of course, for finding a way of making most skillful use of it!!!
It looks like translation quality really isn’t bad. I think for just translating words Google is more reliable than for translating text in context—which is of course much more complex and error prone.
I just caught one case where it shows only the first of several meanings:


 ; also I don’t know if it has the required quality.
; also I don’t know if it has the required quality.