We updated BuddhaNexus.net with a number of Sanskrit files that are found on SuttaCentral and that are not sourced from the GRETIL database, mostly Sanskrit fragments as well as the Udānavarga de Subaši.
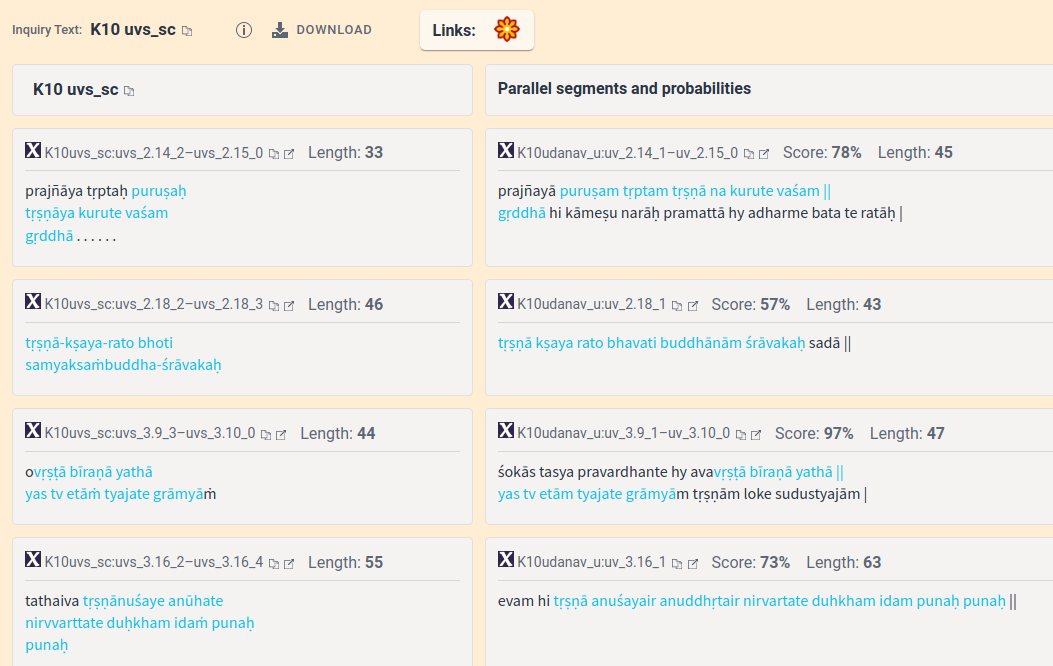
We also added links to SuttaCentral on all Sanskrit files that can be found on SuttaCentral.
You can also download these files (in table and numbers format) in a spreadsheet.
Our plans for the next year include full matching of all Pali and Sanskrit files (and possibly also Tibetan) so all parallels between these languages can be found more easily. This will be the first major step to cross-lingual matching using AI.
Another interesting project we are currently engaged in is the full AI English translation of the Chinese Taisho and Shinsan collections. I hope to have this online in April/May this year.
