Wow. You may have found another bug. There are 82467 ṃ and 6 ṁ in the suttas. Maybe the 6 are typos. In any event, I have now made the two dotted m’s sound the same. Here are the revised sounds. This is listening torture. The first two are soooo close but not.
saghe (not a real word) sa ṁ ghe sa ṇ ghe (not a real word) sa n ghe (not a real word)
That’s worrisome. Added to Release-Plan to investigate.
Oh… please don’t be too enthusiastic about his one. ṃ and ṁ are not different sounds, they are just variants in spelling and mean exactly the same. Some scholars prefer one way, some the other. On SC you can toggle between the two by typing ALT+M, see Easter Egg 🥚 1
I simply use ṁ because I have an easy keyboard shortcut for that one.
And please compare the “saṁghe” in your first voice example to the “saghe”, “saṁghe”, and “saṅghe” in the second—there’s a clear difference! I mean in the previous example I still can’t detect any “ng” sound at all while in all the latter examples there is one (slightly different for each), even in “saghe”. So I’m not sure what Aditi is doing here…
The first sound example is wrong. You did indeed find a bug.
It was wrong because the ṁ was passed directly through to AWS Polly Aditi, who shrugged her shoulders and said “What is that?”. Aditi does not know ṁ, it is not one of her phonemes. So we heard what Aditi guessed, which is…random. The fix was to translate ṁ to ŋ for Aditi. SCV already handled ṃ by translating it to ŋ.
I’m really glad you’re able to hear the differences in the latest sample. I really struggle.
Here are the Aditi phonemes for each of the four words:
sɐgʰe
sɐŋgʰe
sɐɳgʰe
sɐngʰe
I can see the differences. You can hear them. Maybe one day I will too.
The important thing is that there are audible differences. The actual pronunciation can vary between voices, but the sounds should be distinguishable for any given voice. Better voices will speak Pali more clearly so that we can all distinguish each syllable. Aditi works for now, but should be replaced with better alternatives as they become available.
I only hear the differences as long as the words are in a nice list next to each other and I know the order in which they are going to be pronounced. If I would encounter one of them alone it would be really hard to tell which one it is!
But it would be interesting if my friend can distinguish them. Next time I meet her I can ask her.
Actually, that is what I think saghe should sound like; but idt doesn’t.
As for the word saṅghe / saṁghe, I think they are not different words, but the spelling preferences have changed over time, and so we sometimes find different versions in a text. But this is probably a guess, and maybe someone else has more reliable knowledge about this?
I think overall, Aditi is doing a good job, and the more I listen the more I get used to her way of pronunciation.
One other thing I have to get used to is when she inserts vowels where there are none, or seems to change the vowel. Or at least to my ear it sounds that way.
This happens for example when there are double consonants, but not always; it sounds as if there is a vowel in-between. Another case is when there is a tilde ~ over a letter, like ñ. Sometimes it sounds as if there is a vowel, mostly e, inserted, but not always. And in cases when a word ends with -iṁ, I’ve already come across instances where it actually sounded more like -aṁ.
I’m really not sure if this is only to my ear, or if other people notice the same?
I’ll defer to the ordained on this, but it does make sense given the span of time. There is also n with dot under in the mix. I have been working hard to apply specific and different phonemes to each of these subtle sounds using this as my guide.
Double consonants are one of the reasons Aditi and Raveena are candidate voices. The English voices don’t articulate the consonants separately. The AI voices are patterned on human voices, so we may be hearing the particular human’s intonation of double consonants. I think the problem here may be cadence. When we chant, each syllable normally takes a beat and long vowels take two beats. With chanting cadence, the space between consonants is heard as nothing at all because it is the space between sounds. Aditi has conversational sloppy cadence. That is regretable and also why eventually we would need to replace Aditi.
I speak Spanish and the ñ sounds just like Español. There is indeed a vowel turn in this odd sound. When we recite the Spanish alphabet, we say “énye” here. That is my understanding. Pali may have different requirements.
I have noticed this as well and have tried to fix it but apparently failed. Perhaps this sound combination does not occur in Hindi. Inconsistency of pronunciation is the sign that Aditi is making things up. This will be tricky to fix given her disability.
You and I speak multiple languages and may be more sensitive to audible differences. Single language people will struggle more I think.
Thank you for listening! You are providing great feedback. Aditi’s recitation will be common to all SCV listeners. My hope is that listening to Aditi’s Pali alternating segment-by-segment with the listener’s native language may bring us all together in recitation.
Hi Karl, I have a question / feature request: Is it possible that when starting to listen to a sutta the user can have some information on how long it would take to listen to this sutta (depending on which option is selected: translation only, or Pali and translation; and probably that’s also different for different voices)?
When reading a sutta as a sighted person I can very quickly have an overview how long my text is, and so have a basis to decide whether or not this is what I want to read right now. Listening to suttas on SCV doesn’t offer this information—or did I miss something?
I have no idea how big a challenge this is on the technical side, or if it is at all feasible—but would be very nice to have it!
@Aminah, this feature is subtle and we should all put our heads together.
What is know to me is the number of segments.
DN33 has 1158 segments
AN5.233 has 12 segments
DN33 English takes about 2hours to listen to. And I’m guessing that DN33 Pali/English would take 4 hours. That’s a lot of time. The thought occurred that one might want to break down such listening into manageable logical portions, especially for offline listening MP3 downloads. This consideration made me scratch my head at the prospect of splitting a long download at an arbitrary segment boundary and that seemed…abrupt and undesirable.
SCV breaks long suttas into numbered sections if they are present. DN33 has twelve such sections. The SCV sections are different than Bhante Sujato’s translation of sections. By Bhante Sujato’s translation, DN33 has three sections. Ones-Fours, Fives-Sevens, Nines-Tens.
With sections, we could break up long recitations at SCV-section boundaries (vs. Bhante Sujato section boundaries, which are supersets). Then we could have an option for people to give a desired time for a single MP3 file. We would use that length to break up suttas or reading lists of suttas at SCV section boundaries. E.g., it would break up DN3 between Threes and Fours.
Today, it is possible to get playing lists that would take a full day or longer to listen to and this translates to a challenge for the file download feature I am currently working on. I can’t think of anybody liking a 24 hour MP3. I personally would like shorter than two hours, perhaps 90 minutes at most.
In terms of priority, I think this has to be part of V1 because of file downloads.
And in terms of Sabbamitta’s request, that’s (0.5d) for just the SuttaPlayer time estimate.
I made you read all the above to get here.
So eg. ṁt becomes nt, ṁp becomes mp, and so on. Because of this rule, it always seems to me that in Pali, the correct spelling should be saṅgha. Sanskrit, however, may be different, but I don’t know enough about it to say.
In the case of ṁg or ṁk, the nasal (ṅ) is in fact exactly the same sound as the anusvara, so the difference is a mere spelling convention.
Manuscripts vary between one and the other. In theory, this might be meaningful: we might find that, say, manuscripts from a certain lineage nasalize in a certain way; or that early and late manuscripts differ in some way. But I have never seen anything that suggests such a finding.
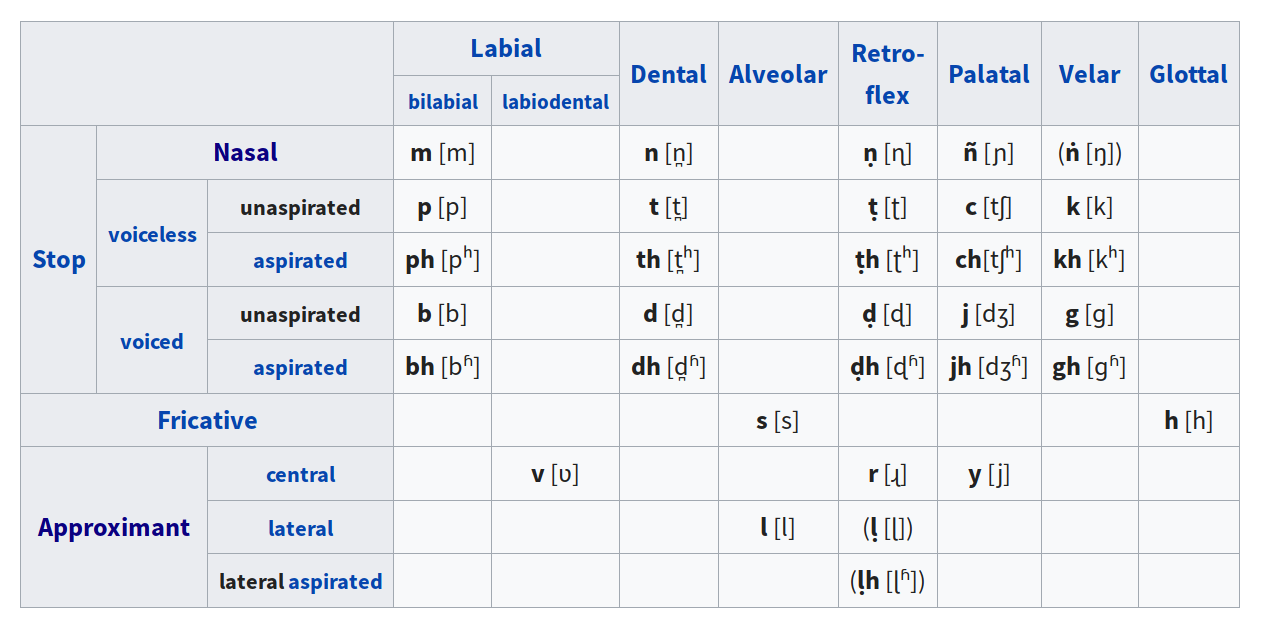
Bhante Sujato, thank you very much for this definitive table.
@Aminah, I shall need to work through this entire table for v1.0. Let’s call it (1w). This is not a minor undertaking. The challenge is to handle vowel/consonant rules. It is also critical to get Aditi’s pronunciation aligned with expectations. If you want a December release, then we should push file download into v1.1 to work on correcting Aditi instead. Or we can delay v1 till Jan.
I would rather guess that Pali / English would take more than double the time of the English. The Pali is very repetitive, and the English often abbreviated.
ṇ is a different sound: it’s retroflex, along with ṭ, ḍ, etc. But that is a fairly rare sound, not found in many modern languages, Tamil being an exception, I believe. So I would guess that the voices don’t support it. Hardly any modern speakers of Pali use it, either.
If we can get it happening, great. If not, it would be acceptable to substitute the retroflex with the corresponding dental sounds (i.e. treat them as if the underdot does not exist.).
You’re right, it wasn’t.
But the actual sounds you heard were:
sɐgʰe
sɐŋgʰe
sɐɳgʰe
sɐngʰe
In other words, Bhante found a bug in my Pali/IPA mapping. And I edited my former post to keep Aminah from getting a headache as she tries to follow these posts:
saghe (not a real word) sa ṁ ghe sa ṇ ghe (not a real word) sa n ghe (not a real word)
My only interest in keeping a focus on a December release was to try and help you with a release goal you set above (without any meddling from me :- ). From my point of view the proto version is there and available to use so there’s no real need to rush to release. Of course we want to integrate with SC, but I sort of suspect the dev team will have enough to be getting on with for the next month anyway.
What I’d propose, is shooting for a Jan release, but sticking closely-ish to the release objectives of 1) getting Pali pronunciation to a satisfactory standard and 2) and only taking on ‘low threshold of entry’ new feature requests (ie things that will make it easier for new users to make use of it such as, the suggested suttas idea) with all other new features ideas going on the wish list for a later release.
That said, completely from the angle of a ‘pleading earlier user’ (ie. a total abuse of any influence I might have), if possible I’d encourage making a v0.9.1 release (sorry if I’ve got the naming convention wrong) which will just handle the “Untranslated segment causes playing to stop” bug and “Auto-play sutta after launch sound” feature on the current RP.