From @blake, moved here from email, discussion with him and @vimala.
here are my thoughts, which are particularly bent on eliminating sutta uids created only to express parallel relationships.
First early on was mentioned “supersets”, or when there are multiple uids which are parallel to one id.
I suggest this could be done with commas or hyphens:
{
"uids": ["ea9.7", "t792", "an1.1,an1.2,an1.3,an1.4,an1.5"]
}
Commas are not normally used in uids, by putting all the uids in one string it is clear they are as a group parallel to the others. It requires a parsing step to recognize multiple uids are in a single string but that’s okay.
And as for ranges:
{
"uids": ["ea9.7", "t792", "an1.1-an1.5"]
}
With fully qualified uids this is viable.
In terms of parallel calculation logic hyphen ranges would be for the most part substituted with commas (could be considered an abbreviated way to express a comma separated list of uids), but the use a hyphen could be used as a hint to the presentation.
Is this complicated to display? Kind of, but it’s not too bad. When displaying the parallels for ea9.7, it can just show an1.1-an1.5 as a parallel. When displaying the parallels for an1.1 through an1.5, it shows ea9.7 as a superset parallel, while technically tricky it’s possible using rowspan to do something like this (quick mockup - not exactly what it’d need to look like):
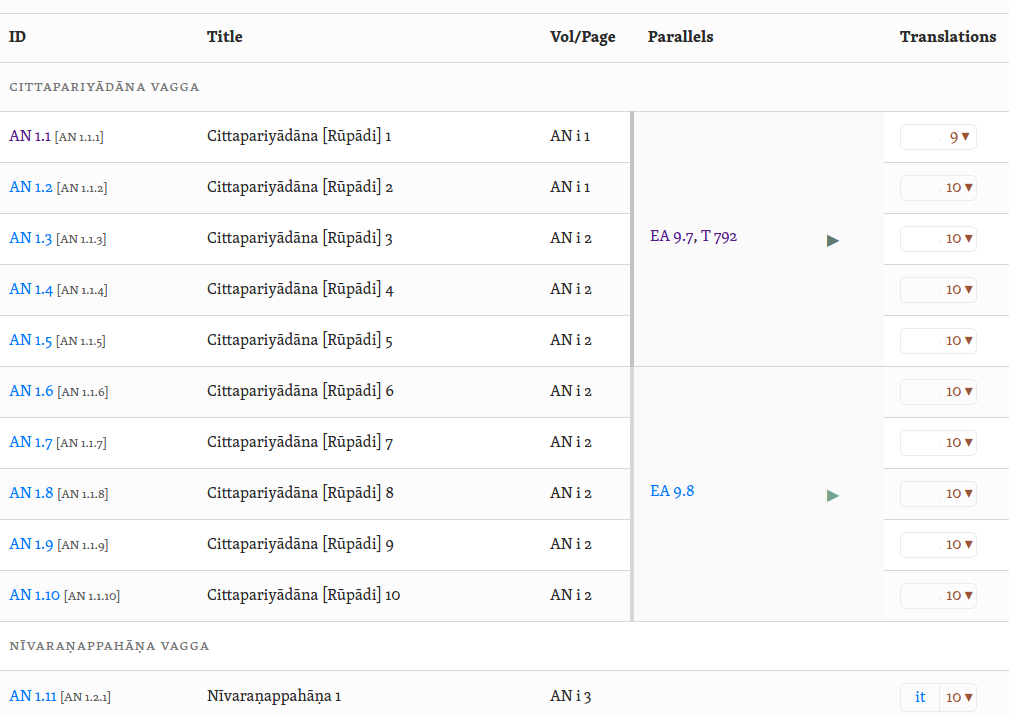
Which I think could be pretty cool - and yes overlapping ranges can be handled using a combination of extra cells, rowspan, colspan and black magic.
The other kind of relationship is a “subset” relationship defined by ids within a text, and I suggest the same syntax be allowed: Use commas or a hyphen and always prepend an id with a hash even if it’s part of a range or comma group:
["dn2#wp11-#wp20"]
Or in the case of commas:
"dn2#wp11,#wp21"]
While you could fully fully qualify all uid#id range references as in ["dn2#wp11-dn2#wp20"] I feel this is overkill, simply prepending all ids with a hash should suffice as the '-#' and ',#' combinations are impossible to interpret in any other way, they must belong to the preceding uid. Another reason to dislike fully fully qualified is that overwhelmingly the use case for this will be multiple ids from the same sutta, I wouldn’t even like to support something like: "dn1#wp20-dn2#wp146" even if it’s not technically impossible it should probably be illegal just to simplify things. Final reason to dislike it is that it will be closer or identical to the form used in the URL: We definitely aren’t going to say /pi/dn2#wp11_dn2#wp21
So what I suggest is the following:
###Superset Relationship
When several things are parallel to one thing:
["ea9.7", "t792", "an1.1,an1.2,an1.3,an1.4,an1.5"]
or
["ea9.7", "t792", "an1.1-an1.5"]
as an abbreviated form.
This should be displayed where possible as being a connected group. Where not possible (or if it’s clunky) to visually represent this relationship we just do our best.
Uids should always be fully qualified, instead of an1.1-5, it should be an1.1-an1.5, although presentation logic is allowed to collapse this down to the prior form.
###Subset relationship
When a part of a thing is parallel to a thing
["uid#id"]
or
["uid#id1-#id4"]
or
["uid#id1,#id2,#id3,#id4"]
ids in a range or comma list should always be written in full and be prefixed with a ‘#’, this is to clearly disambiguate them from uids.
It gets a bit nutty to combine a superset and subset relationship (i.e. parts of multiple suttas, are parallel to another sutta) and it might be better to explicitly forbid it and only allow 3 types: The straightforward uid to uid, the superset and subset relationship, and not allow a superset of subsets.
Please note all of this is about representation in data, not in URLs or presentation.
Since the issue of hyphens in ids came up: It is easier if they go, but it is technically possible to deal with them, as you can use a regular expression to identify parts of the string which are text ids, such a regular expression can be automatically generated by reading all the ids from the texts and finding the common alphabetical-hyphen prefixes, and then that can be used in the parsing step.
Hyphens in uids are not a problem, the server at any time knows every uid in use so it can trivially and accurately identify uids within a string regardless of their component characters.