There are only few people in this world who are crazy about Dhammapada parallels. My friend Ven. Anandajoti and myself are two of them.
So when Ven. Anandajoti approached me last year to make me aware of the work of Sebastian Nehrdich, I was very enthousiastic because I could see the huge potential for us to find parallels. Sebastian was using a neural network approach to find similarities within the Sanskrit texts of the Göttingen Register of Electronic Texts in Indian Languages (GRETIL). However, the display of his output was very rudimentary and not very easy to work with.
I approached Sebastian with the request to run the Pali texts through the neural network. The initial idea was to have this for just the EBTs on SuttaCentral. Sebastian agreed and I, Bhante Sujato and Blake constructed the necessary input files for the neural network from SuttaCentral’s Bilara and html files in combination with SC’s hyphenation code.
In order to create a better user interface I started making a UI for this, based on SuttaCentral’s system of webcomponents. When I showed this to Sebastian, he became enthousiastic about it so we decided to combine forces. Now, almost a year later, we have a launch date for our new BuddhaNexus website at the end of June and the project has become a full-fledged 3-tier website, with 4 developers working on it and backed by the Numata Centre of Buddhist Studies at the University of Hamburg. The site hosts all available digitized Buddhist texts in Pali, Tibetan, Chinese and Sanskrit as well as other Sanskrit texts like Vedic and Jaina. And most importantly, it shows the connections between texts.
In first instance, the site will only be able to show parallels within the same language, but as we have recently been given access to a super-computer from Hamburg University, we will also be able to run the neural network finding parallels between languages.
In the mean time, Ven. Anandajoti asked my help in identifying Hindi parallels of the Dhammapada and I decided to test our BuddhaNexus project with this. It was good test-case that allowed me to test the system and identify bugs. After a few hours of work I had identified over 100 new and unknown parallels in the Sanskrit texts alone and the results are displayed in the below spreadsheet.
dhpparallels.zip (17.9 KB)
Note that this spreadsheet only lists entries that are not already listed in Ven. Anandajoti’s excellent book on this subject:

Some are listed on SuttaCentral, but most of these are not.
In addition to this, I plan to do the same for the Tibetan, Chinese and Pali to identify where Dhammapada parallels are in the entire corpus of texts.
The below pie-charts show that there are a large number of parallels to be found in various texts.
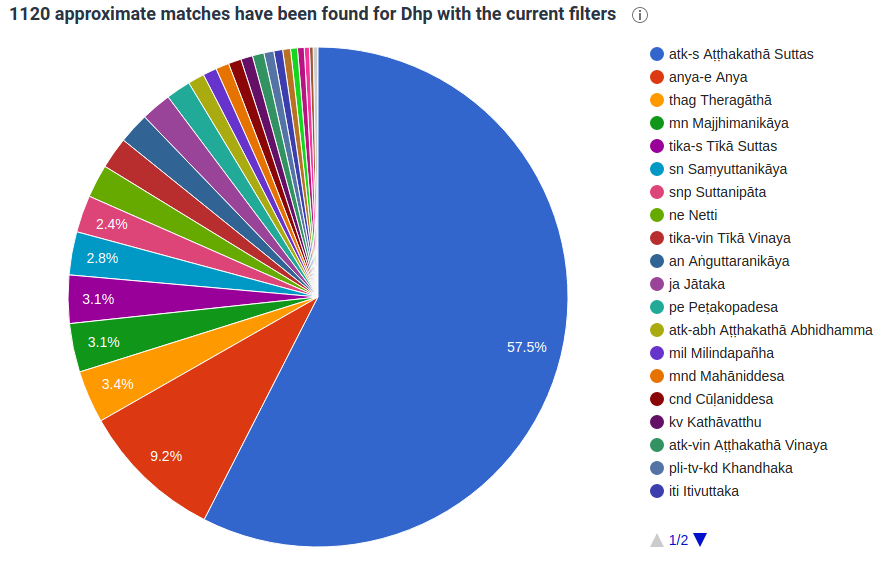
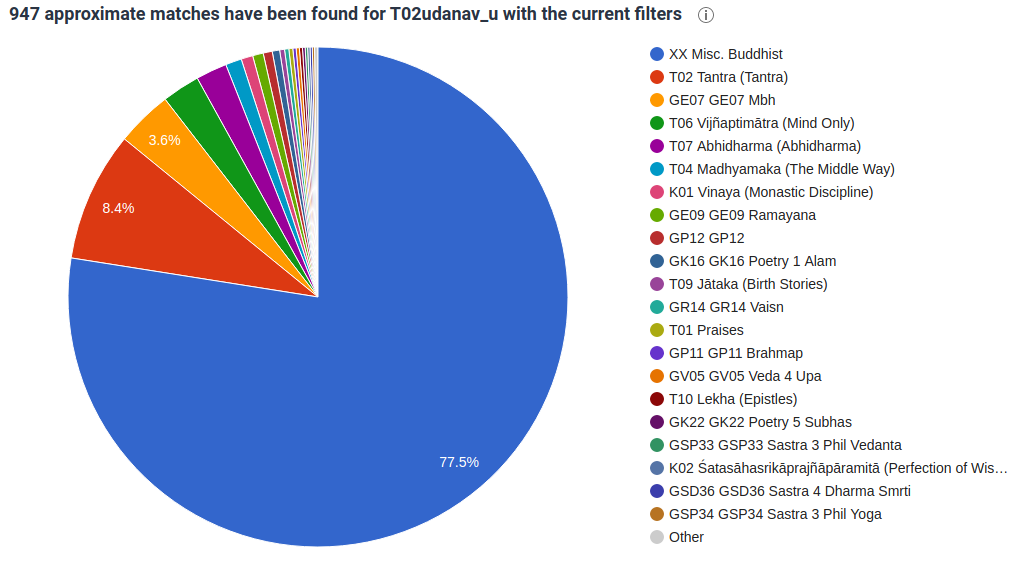


I’ve also added a sankey-chart for the Dhammapada links to other Pali texts:
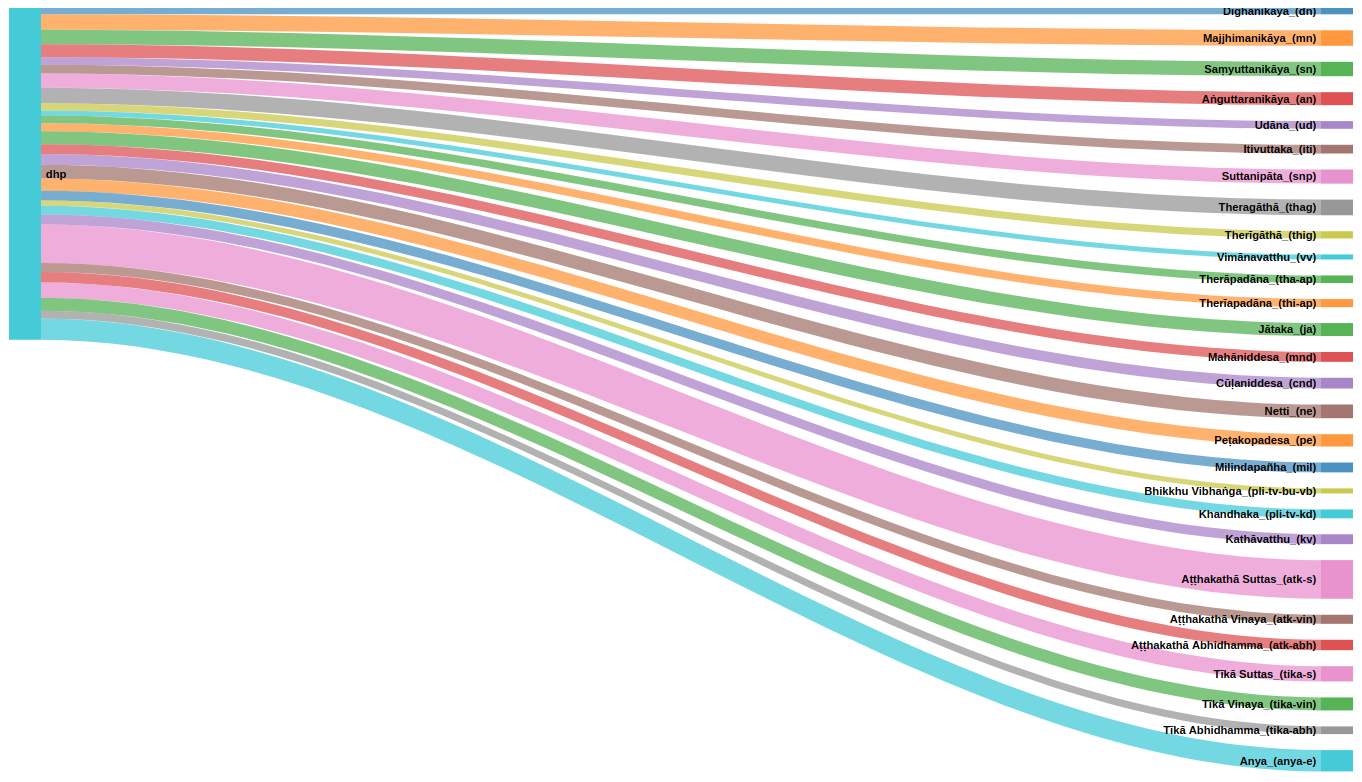
This small test already shows BuddhaNexus’ enormous potential; it will give researchers worldwide a very powerful tool for finding parallels and it will open up previously unknown possibilities in this field.
Of course none of this would be possible without the help and support of so many people. Bhante Sujato helped to create the Pali input files for the network and supported with advice, Aminah helped setting up a ZenBoard and management system and not to forget my old friend from the SuttaCentral STXNext team, Hubert, who joined our fixed team of developers with much needed advice and input on how to handle these huge amounts of data.
I also want to mention here the great work of @lemon, who has been working hard to correct SuttaCentral entries of the Udanavarga and compare these with Chinese and Tibetan texts and this material is extremely valueble for helping us to train our neural network to read and compare different languages but also for me to identify new Dhammapada parallels.
When the site is launched I will post it here.
 Thank you, Venerable. A gift of Dhamma to the world.
Thank you, Venerable. A gift of Dhamma to the world.

